Data Contributors using the API¶
About this guide
This guide provides a basic overview of API documentation in Swagger for non-technical users. It is not intended as a detailed guide for daily API usage, but rather as an introduction to understanding the documentation.
We are currently working on an advanced guide that covers all use cases to provide you with the best experience using the ODM REST API.
In addition to the options available to Data Consumers (retrieving data), Data Contributors can also create studies and curate data (see the Figure below). The main functions available are Create a new study and Curate Data.
Access the API Endpoints¶
Follow these steps to get started on using the ODM’s API Endpoints :
-
Log into the ODM:
- Navigate to the ODM homepage.
- Click on API Documentation on the homepage.
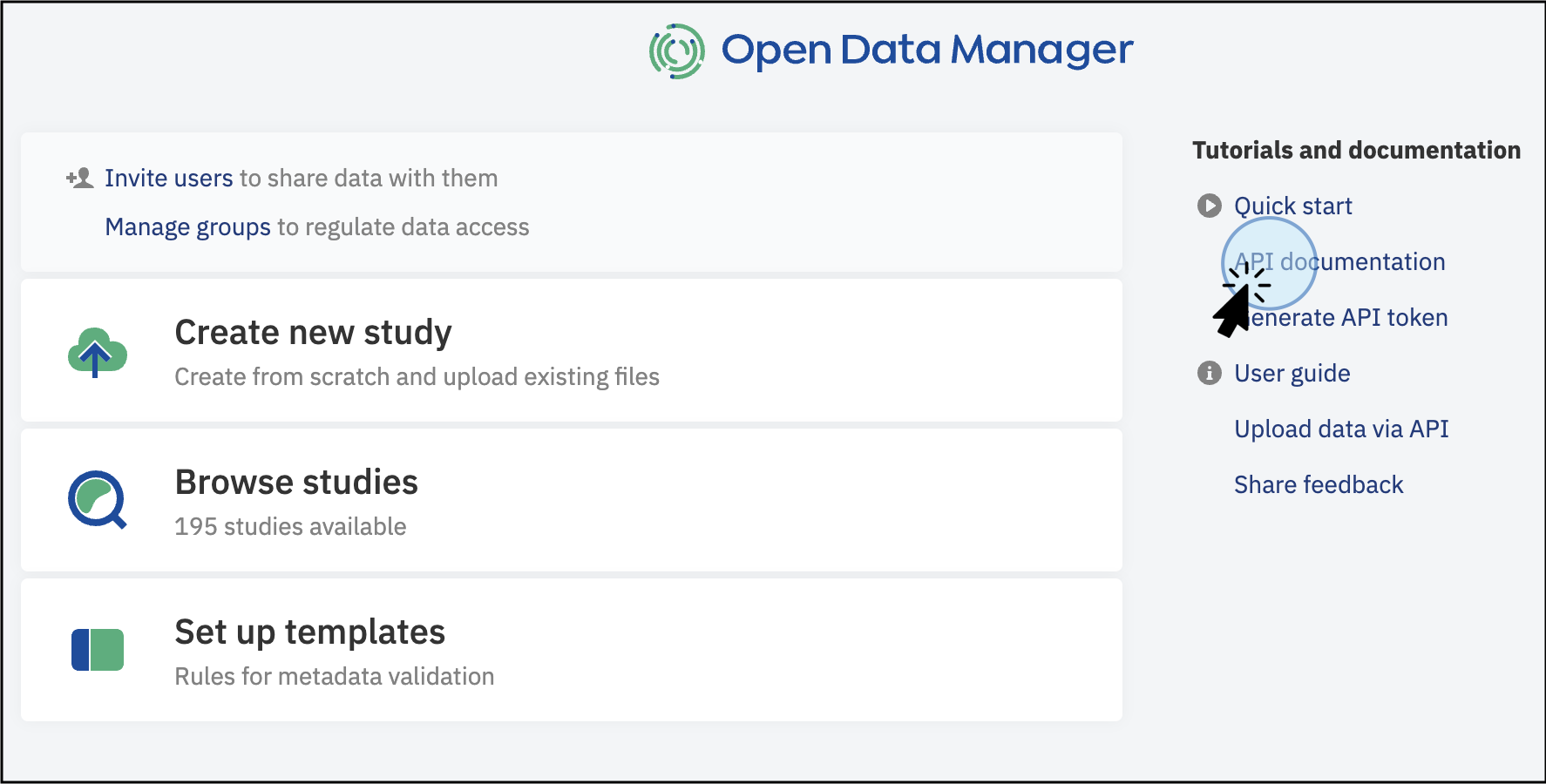
Main dashboard of the ODM. Click on API documentation to explore the available resources -
Explore the API Documentation:
- This action will display the API Documentation window, where you can explore how the data model in ODM is structured.
- In this window, you will also see how the endpoints are grouped based on general use cases.
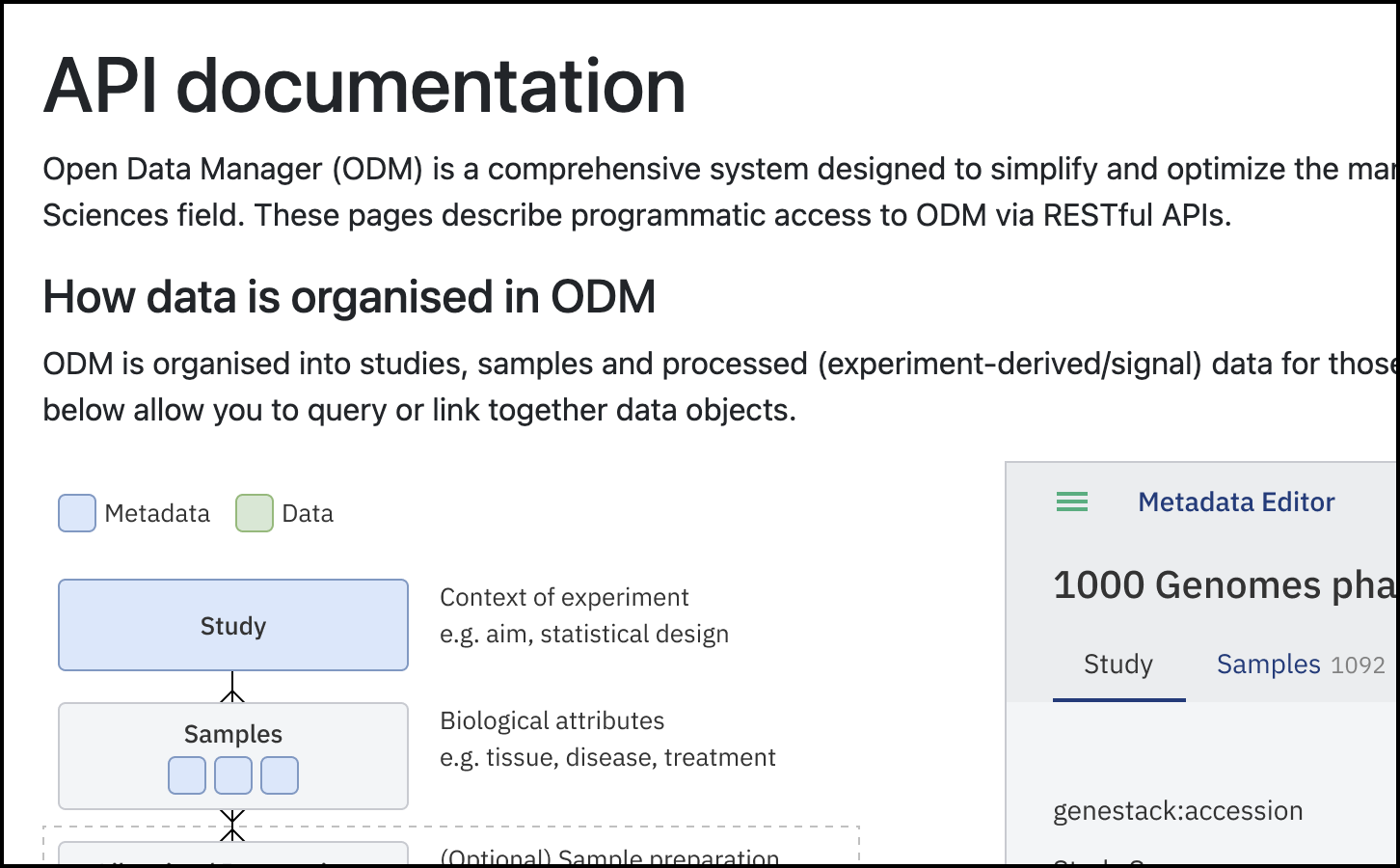
API Documentation dashboard. This window shows the data model structure and where the specific endpoints are located
Endpoint groups explanation
- Query/retrieve data with the list of user endpoints - only these endpoints can be used by users who are not included in the group Curator, also these endpoints can be used by users from the Curator group also.
- Import/curate data with the list of curator endpoints - can be used only by users from the group Curator.
- Data sources - some endpoints can be used by curators only, others by curators and researchers.
- Manage organisation - this section is actual only for users with the permission to manage organisation.
Using Swagger for API Interaction¶
Swagger is an API documentation tool which provides an interactive interface for exploring and interacting with the API endpoints. Its main goal is to familiarise users with the available endpoints, parameters, structure of response, etc. Note that it is not for day-to-day usage or integrations.
Follow these steps to use Swagger effectively, based on your role and permissions:
- Select the Endpoints for Specific Actions:
- Depending on your role (Data Consumer, Data Contributor, or Data Admin) and your goal, select the appropriate endpoints. Examples include retrieving sample metadata, updating a study, or adding new groups.
- Explore the Swagger Interface:
- When you select an endpoint of interest and click on it, a new window will display the Swagger interface.
- This interface allows you to explore available endpoints for querying and retrieving data.
- Accessing Endpoints:
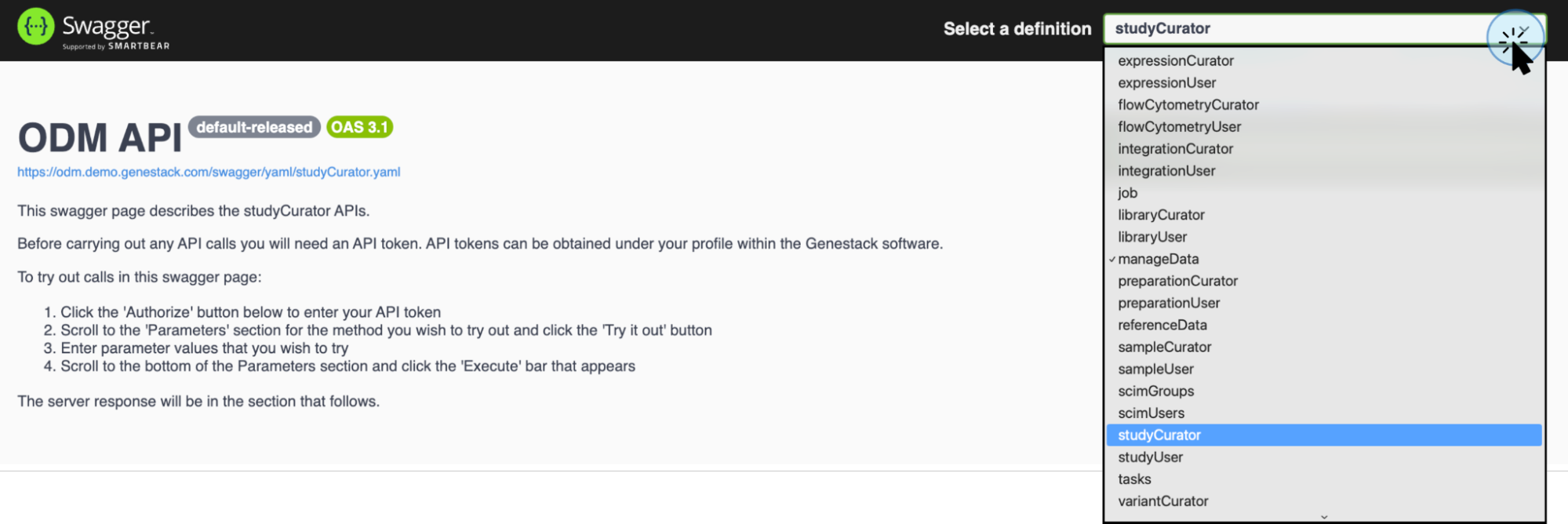
- Use the top right button to select specific functions. For example, the
studyCuratordefinition contains API endpoints specifically for retrieving study metadata.
- Use the top right button to select specific functions. For example, the
API token¶
An access token is required to work with the API endpoints. Follow these steps to create and use an API token:
Generate a Token¶
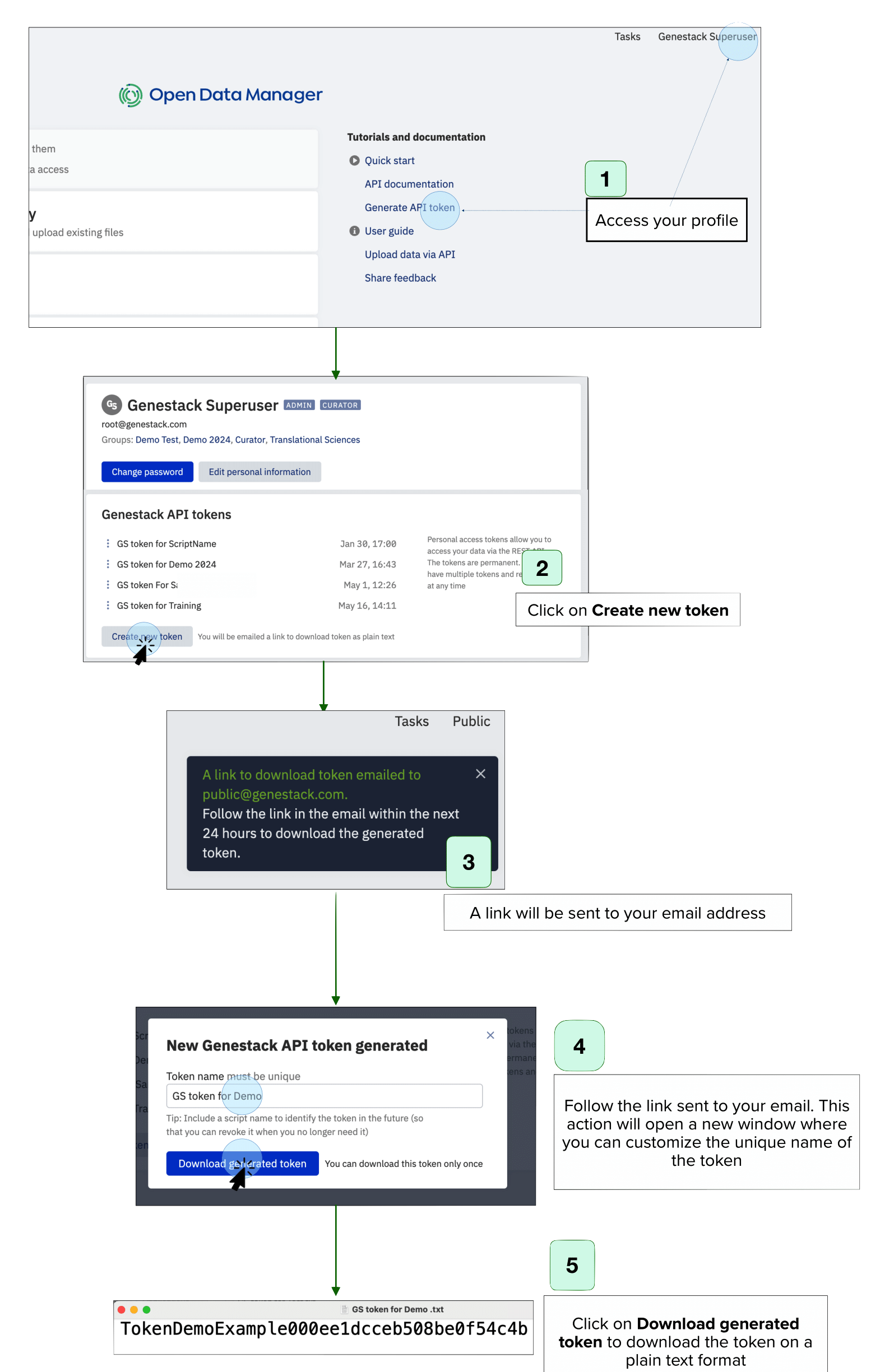
- Access Your Profile
- Navigate to your profile by clicking your username in the top right corner of the User Interface or from the Dashboard.
- Create a New Token
- On the profile page, you’ll see previously created tokens. Click on Create a New Token.
- Follow the link on your email.
- This action will open a new window where you can enter a unique name for the new token in the prompt that appears.
- Download the Token
- Click on Download Generated Token.
- A plain text (TXT) file containing your new token will be automatically downloaded to your local computer.
- Store the Token
- Save the token in an easily accessible location for future use.
Authorize with the Token¶
- Once the token is generated, you need to authorize the use of the endpoints.
- Direct to the endpoint of interest depending on the action to run (retrieve data, stream data, upload entities, etc.)
-
Click on Authorize, select the type of token (Access Token or Genestack API token), and navigate to the specific endpoint.
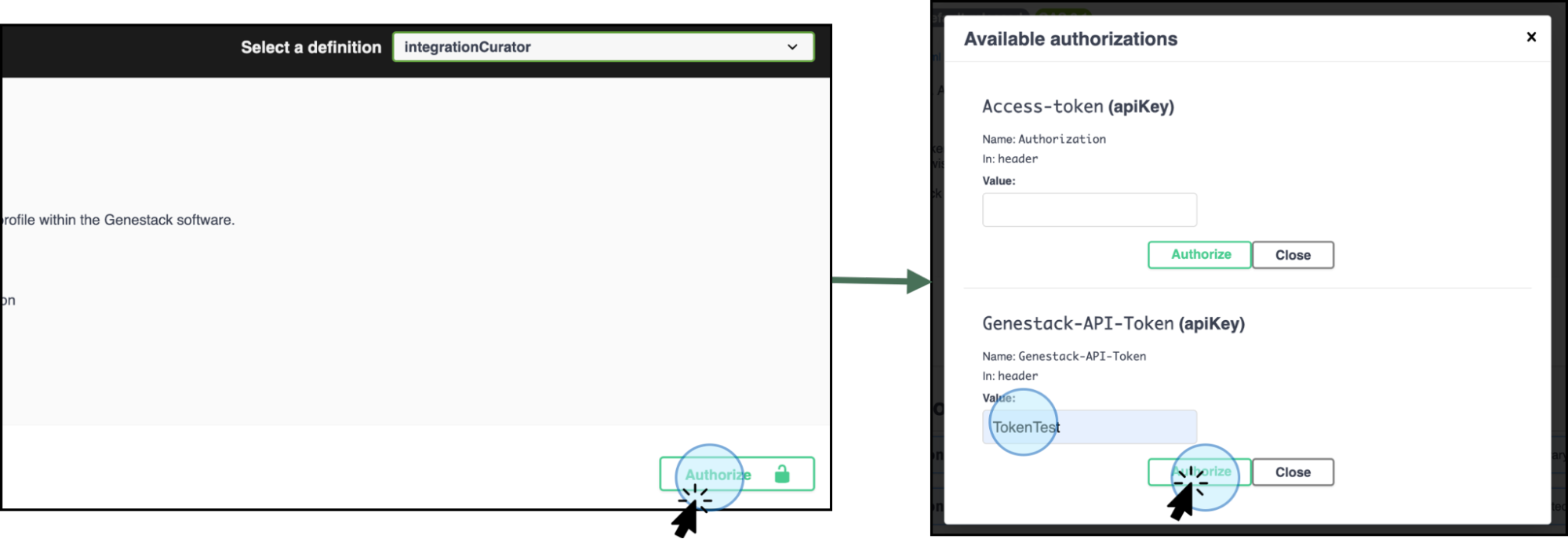
Use your token to authorize access to the endpoints -
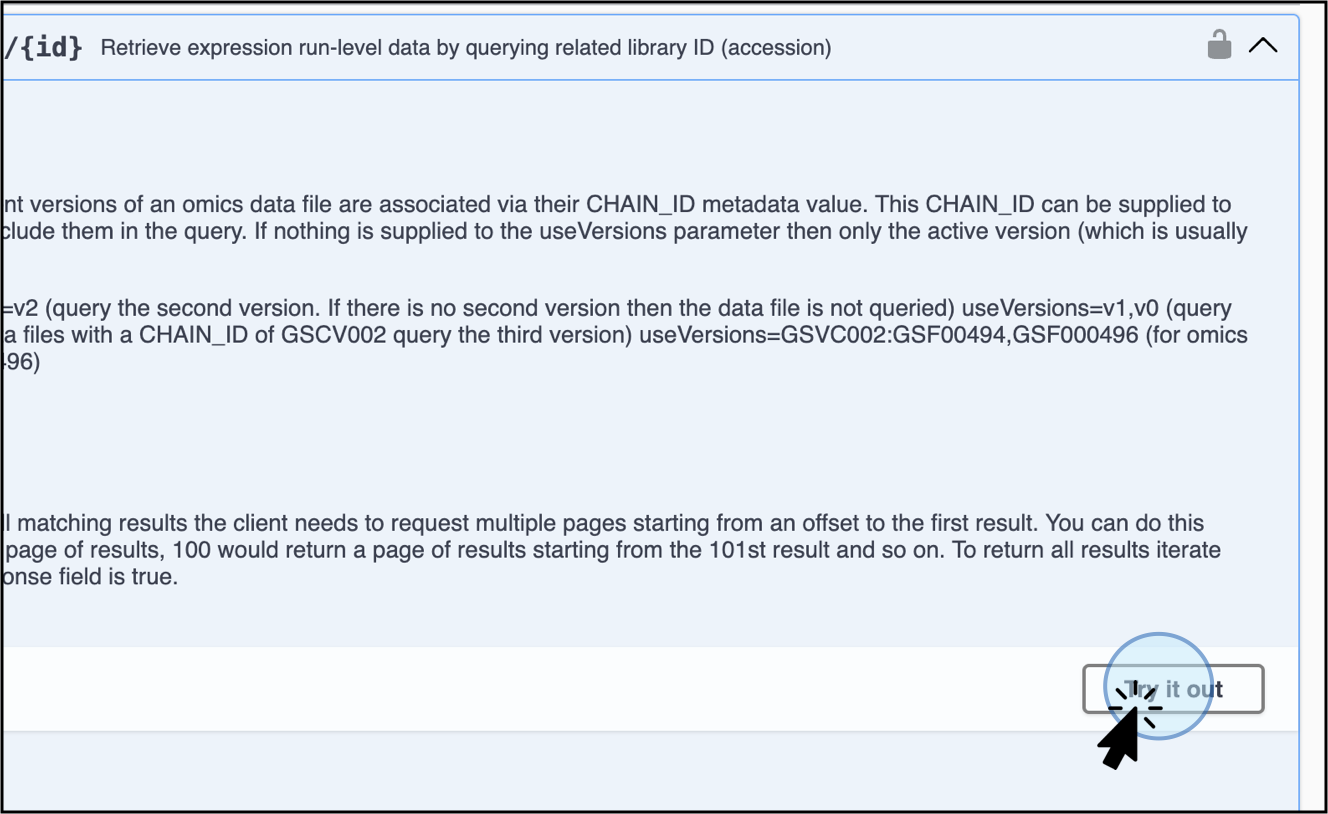
Click on Try it out to activate it. The Try it out step is required for every single endpoint.
The ODM Data Model¶
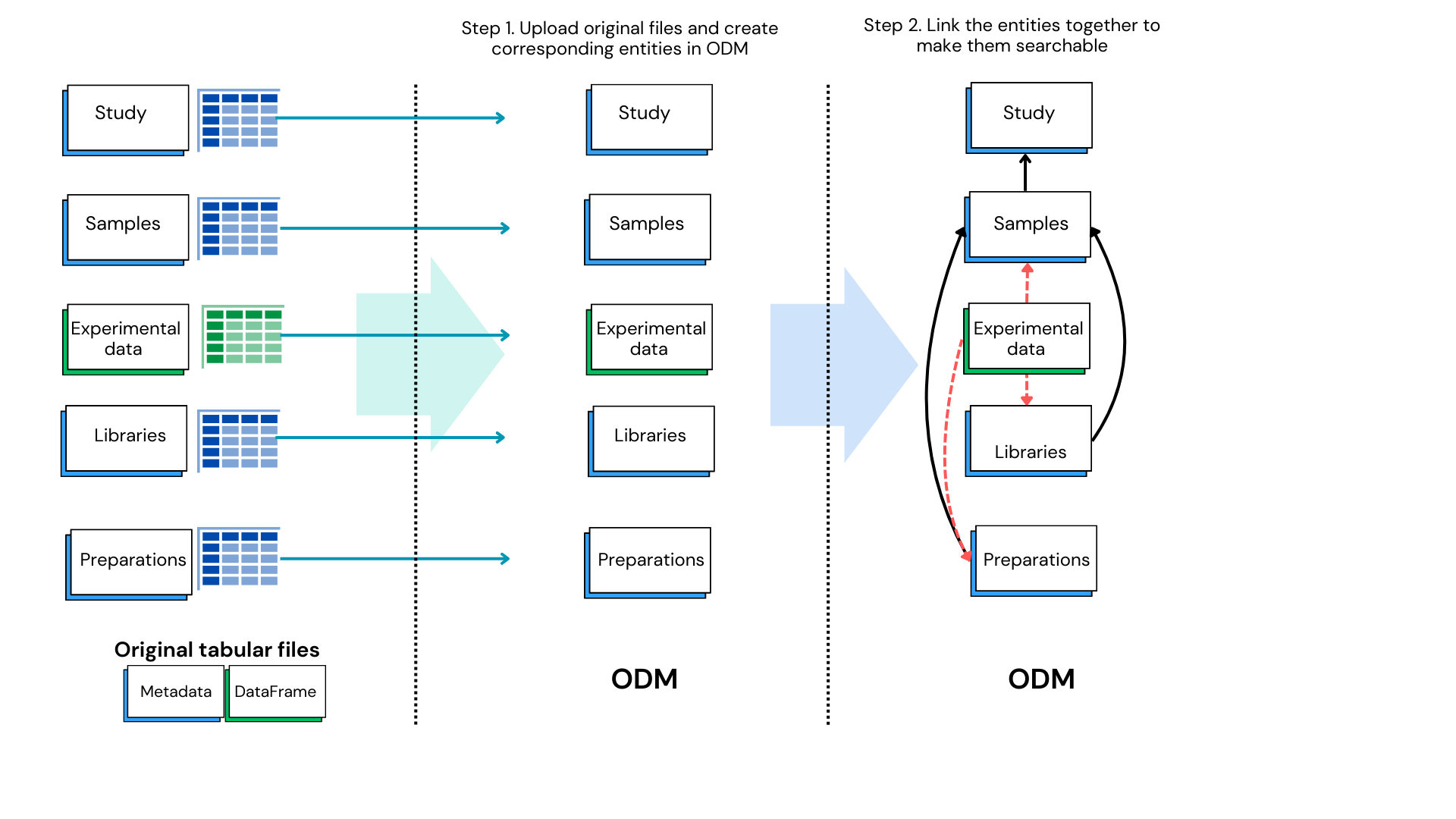
To create a study, you need to perform two main steps:
- Upload your data files, such as study metadata, sample metadata, and experimental data, corresponding to an entity (e.g., TSV file with sample attributes).
- Link the corresponding entities together (e.g., link sample data to the corresponding study).
-
If you upload your file without linking it, it won’t appear in the ODM interface but will be accessible via API.
-
- The ODM Model includes two additional entities to describe experimental design: Libraries and Preparations. Both Libraries and Preparations can be linked to Samples and can be utilized as sample grouping entities. DataFrames, which contain experimental data such as gene expression and flow cytometry, can be linked to Samples, but only expression data can be linked to Preparations and Libraries.
- Additionally, the ODM provides the capability to import and link a cross-reference (xref) mapping file. This allows you to look up genes for a given set of transcripts and vice versa. Mappings are associated with expression data files, but if desired all mapping files can be queried to return all mappings. Currently, all mapping file operations are carried out via API. For more information please check Cross-reference Mapping page.
Use Case Example: How to create a Study¶
Let's reproduce the most frequent use case by creating an entire study using the Swagger interface. Swagger provides a user-friendly interface for interacting with APIs. For this example, we will use the following files:
- GSE60871_Study metadata (TSV file)
- GSE60871_Sample metadata (TSV file)
- GSE60871_Experimental data (gene expression in GCT format)
API Token¶
An access token is required to work with the API endpoints. Review the section above to get a token and activate it.
Uploading Study Metadata¶
- Access API Endpoints
- Navigate to the API documentation from the main dashboard by clicking on "API Documentation". This opens a new window displaying the data model and specific endpoints for each action.
-
Select the Job Endpoint
- Locate and select the appropriate endpoint for the action you want to perform.

Select the Job endpoint to upload a study.
- Locate and select the appropriate endpoint for the action you want to perform.
-
Click on Import study metadata from a TSV file (
POST /api/v1/jobs/import/study) and click on Try it out.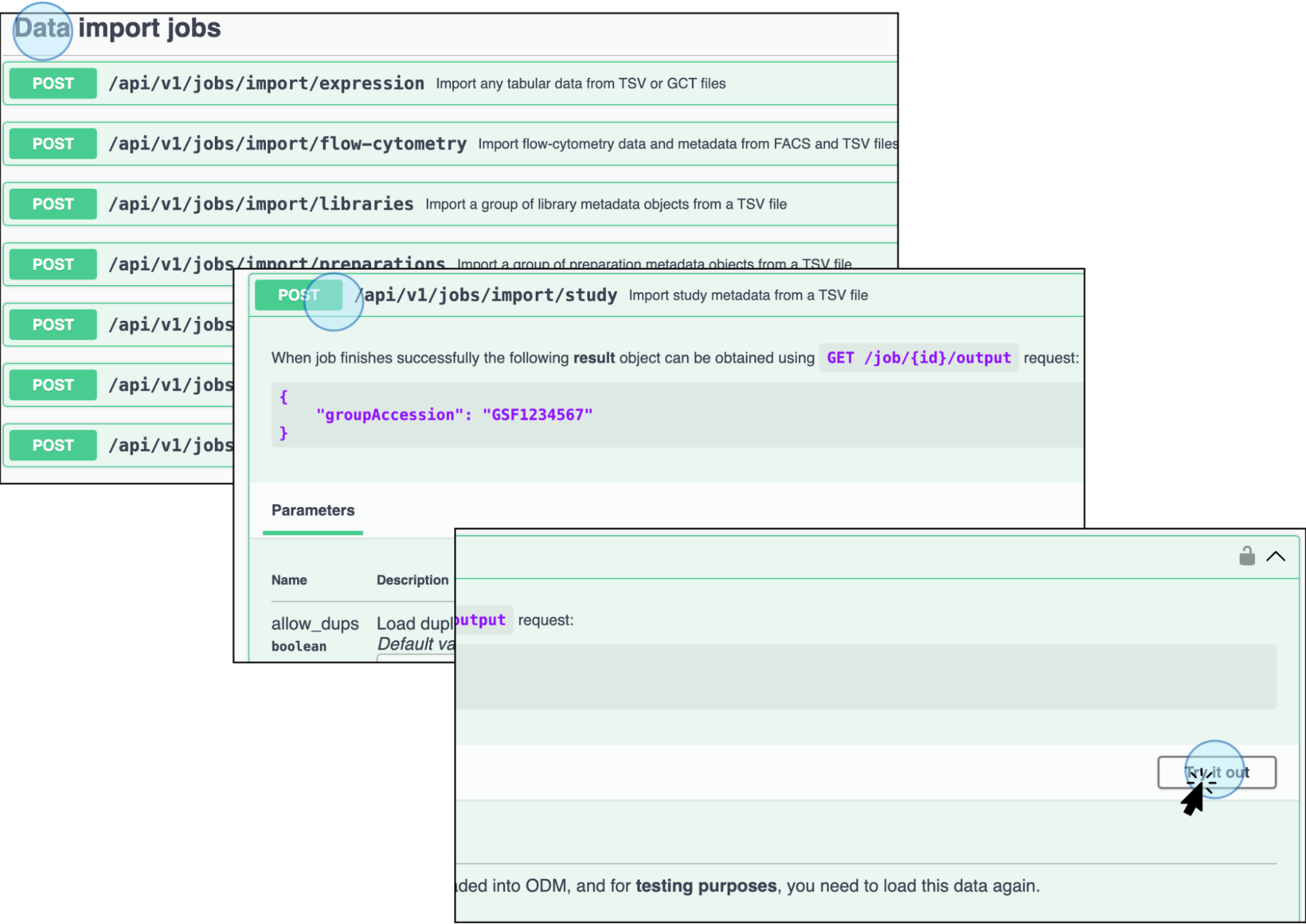
Click Import study metadata from a TSV file to upload the study metadata file and activate it by clicking Try it out -
Enter Parameters: In the parameters section, enter the link where the TSV file is stored (e.g., AWS) and click Execute.
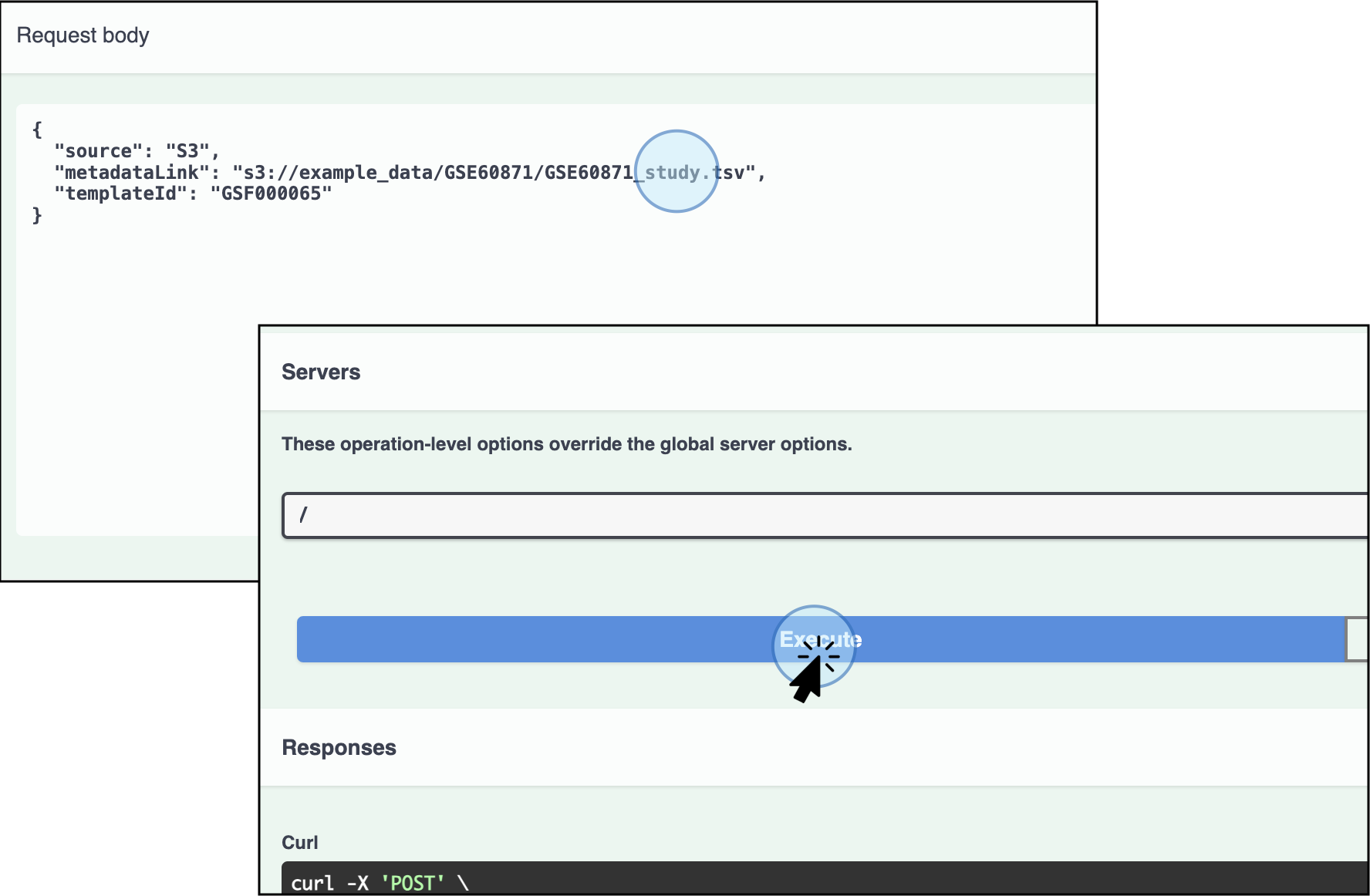
Enter the link for the study metadata file and click Execute The template accession number should either be replaced with the desired template accession number or skipped entirely. If it is skipped, the default template will be applied.
-
Check the Response: The response will show that the study import has started. An execution job ID will be assigned to the import process, 1268 in this particular example. Use the ID to track the status of the import.
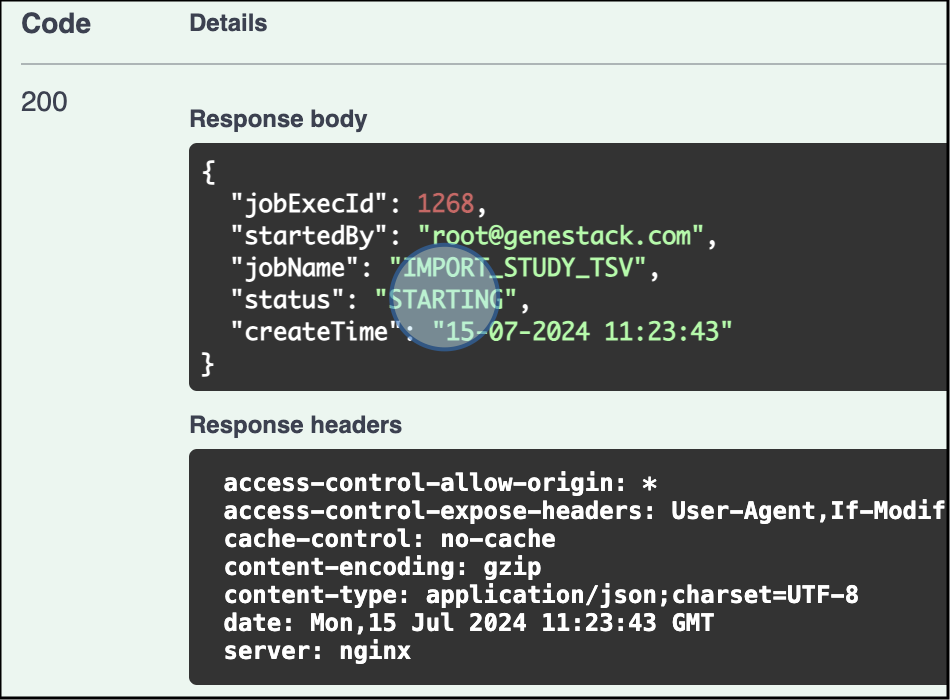
The response confirms the study upload has started and the ID for the Job has been assigned (1268 for this example) -
Track the Import Status: You can track the status of the import with the endpoint
GET /api/v1/jobs/{jobExecId}/outputto corroborate the import process is successful and no errors were detected.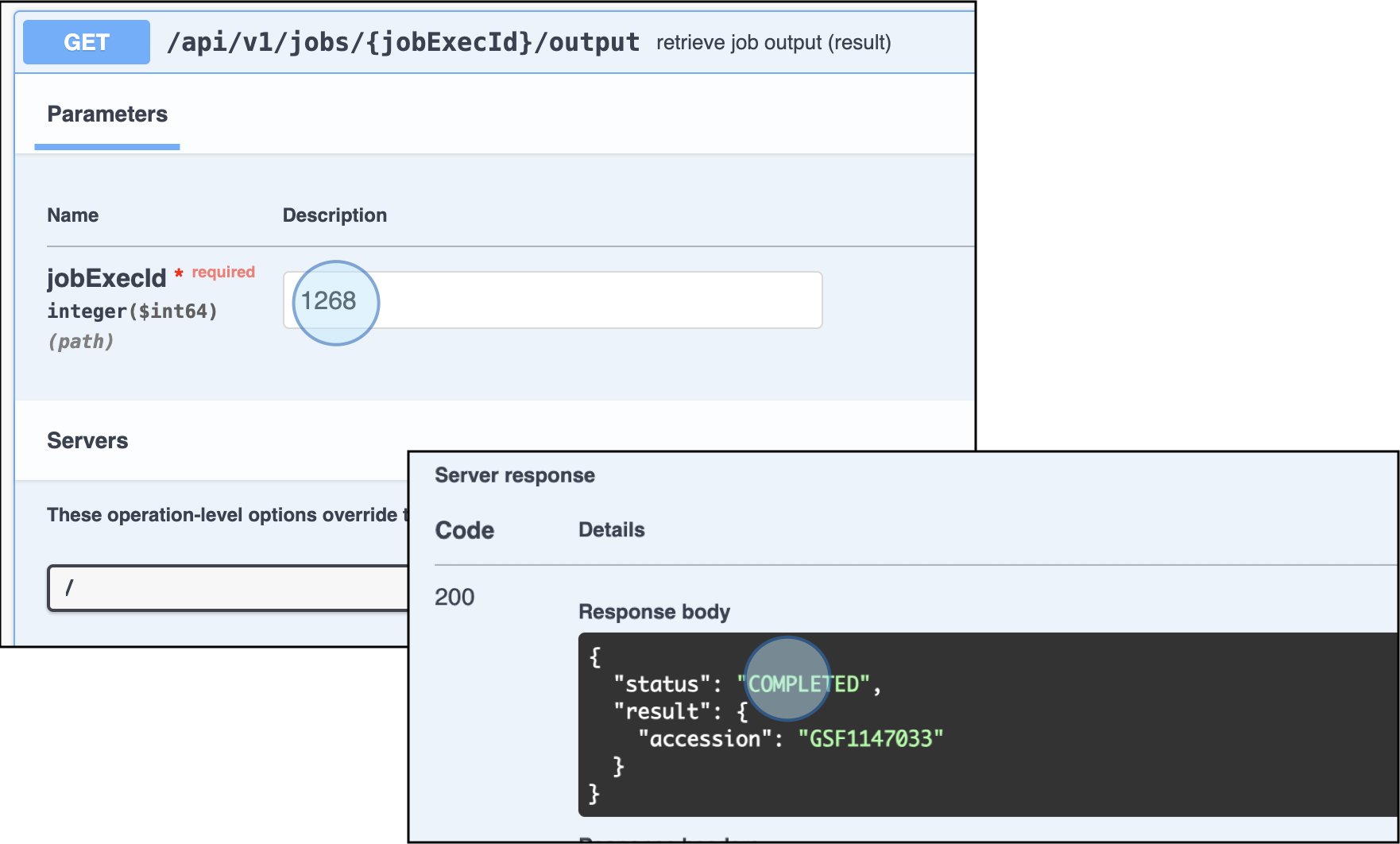
Use the endpoint GET /api/v1/jobs/{jobExecId}/output to review the status of the job import. An accession number will be assigned to the study if the import was successful. Accession number: GSF1147033 -
Explore the Study in the ODM: You can explore the ODM dashboard to see your study. Notice that no samples or data are associated with it yet.
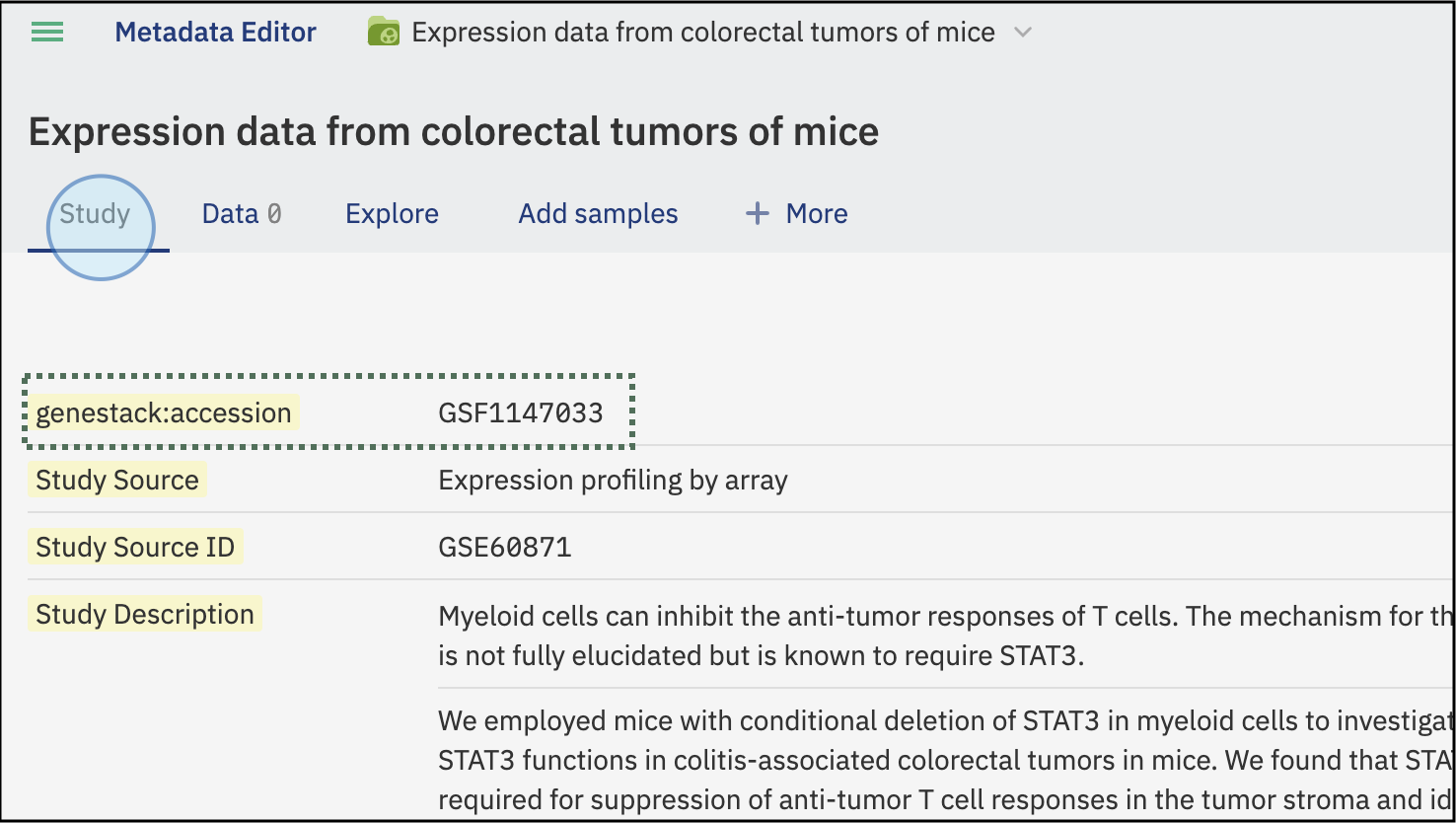
Once the study metadata has been uploaded, it can be explored in the ODM
Notice that an accession number was automatically assigned to the newly uploaded study. This accession number will be relevant to link entities later.
Study Accession ID: GSF1147033
Uploading Sample Metadata¶
Upload the sample metadata TSV file that contains the list of experimental samples and corresponding attributes.
- Access API Endpoints
- Navigate to the API documentation from the main dashboard by clicking on API Documentation. This opens a new window displaying the data model and specific endpoints for each action.
- Find the Job endpoint to upload samples.
-
Import Sample Metadata: Select the endpoint Import a group of sample metadata objects from a TSV file (
POST /api/v1/jobs/import/samples). Review the requirements for the file to be recognized and uploaded.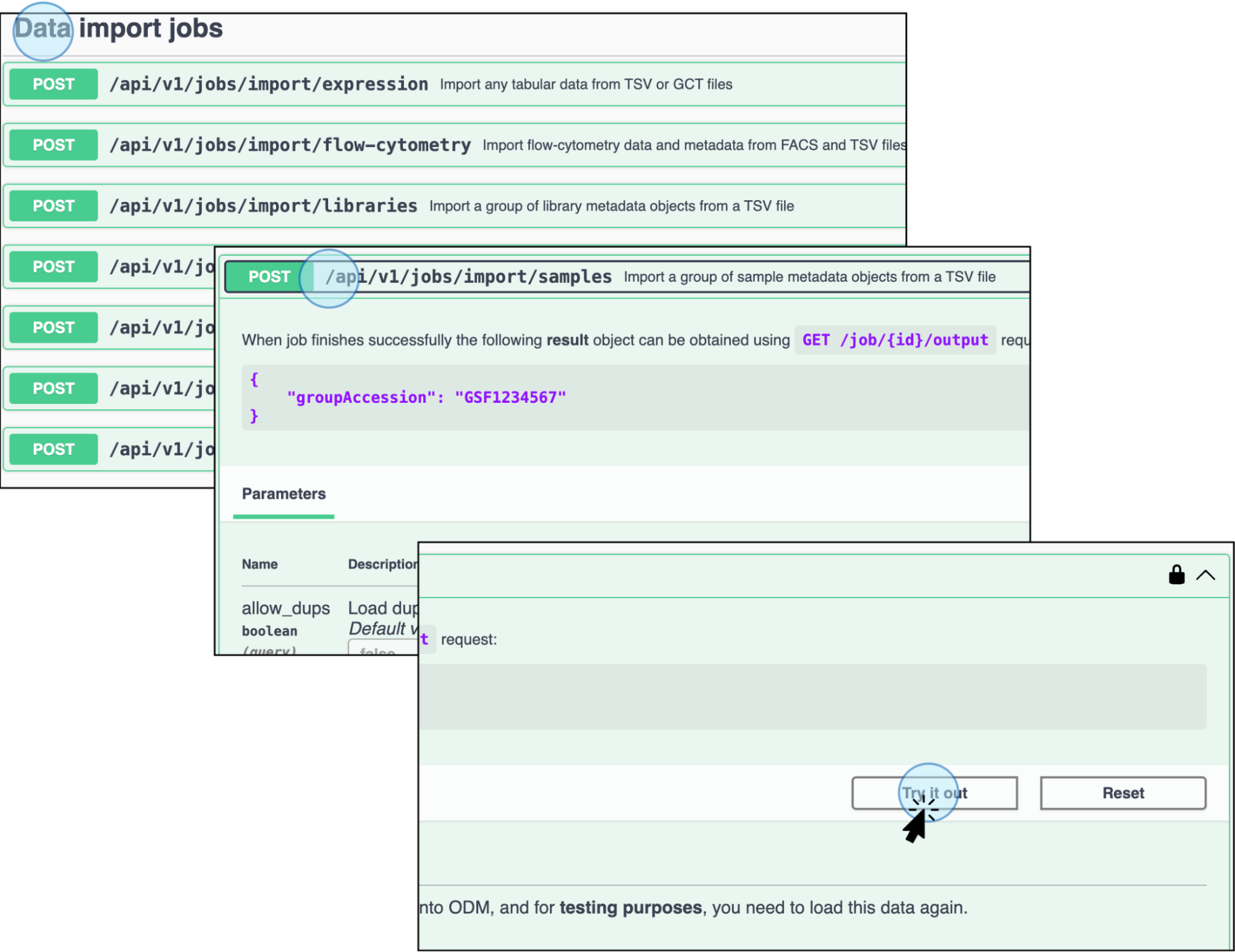
Click Import a group of sample metadata objects from a TSV file to upload a sample metadata file and activate it by clicking Try it out -
Enter Parameters: Add the link to where the file is stored (e.g., AWS) and click Execute.

Enter the storage link for the sample metadata file and click Execute The template accession number should be replaced with the desired template accession number.
-
Check the Response: The response will show that the sample metadata import has started. An execution job ID will be assigned to the import process, 1269 in this particular example. Use the ID to track the status of the import.
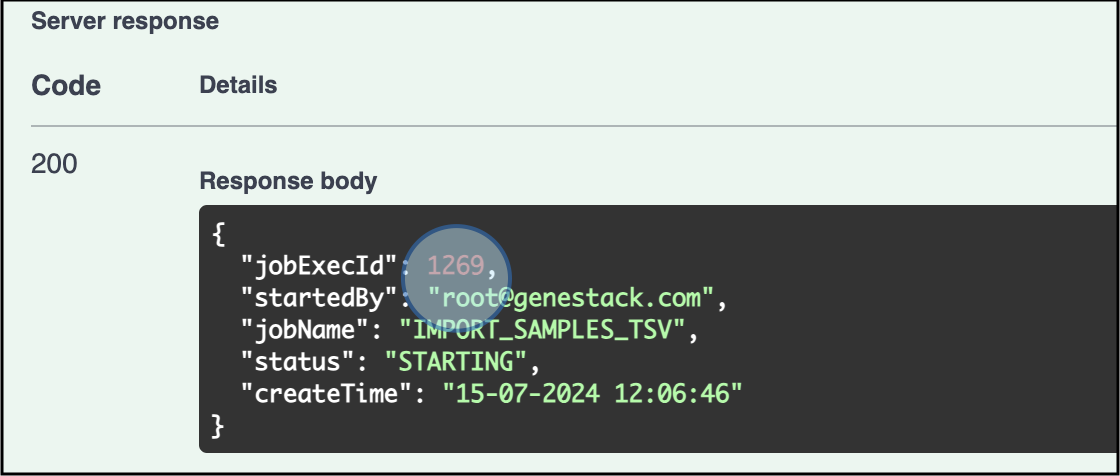
The response confirms the upload of the sample metadata has started and an ID for the Job has been assigned (1269 for this example) -
Track the Import Status: You can track the status of the import with the endpoint
GET /api/v1/jobs/{jobExecId}/outputto ensure the import process is successful and no errors are detected.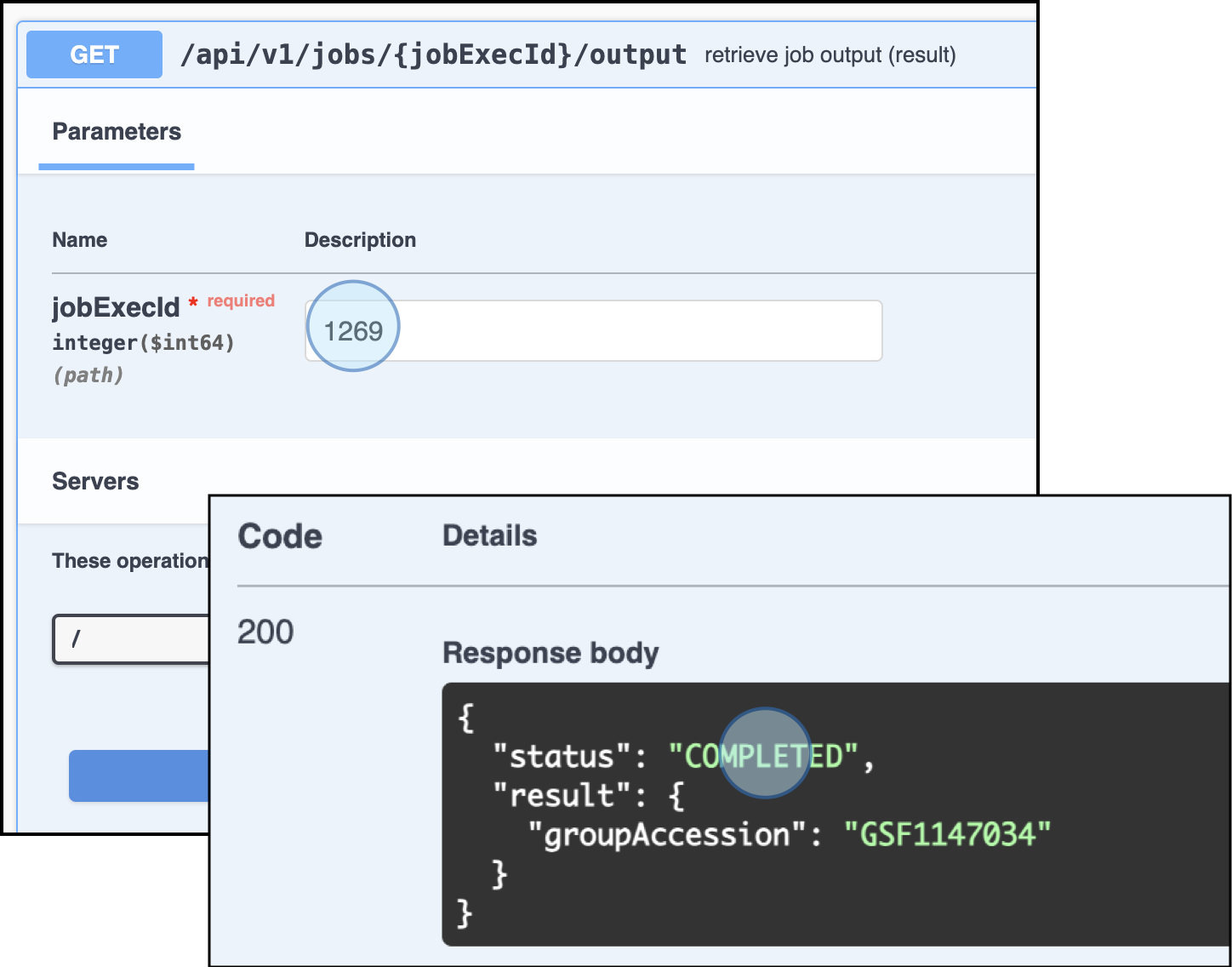
Use the endpoint GET /api/v1/jobs/{jobExecId}/output to review the status of the job import. An accession number will be assigned to the sample metadata if the import is successful
Here you can see Sample Group Accession ID. This accession number will be relevant to link entities later.
Sample Group Accession ID: GSF1147034
Uploading Experimental data: Expression in GCT format¶
Upload the experimental data file that is part of your research (part of the sample metadata and study metadata previously uploaded).
- Access API Endpoints
- Navigate to the API documentation from the main dashboard by clicking on API Documentation. This opens a new window displaying the data model and specific endpoints for each action.
- Select the Job Endpoint
- Locate and select the appropriate endpoint for the action you want to perform.
-
Import Experimental Data: Select the endpoint Import any tabular data or GCT files. The Job endpoint displays a list of options to upload data. You can select the endpoint based on the type of files to upload including experimental data such as flow cytometry, gene variant, etc. For expression data, as well as any type of tabular experimental data not listed, select the endpoint Import any tabular data or GCT files (
POST /api/v1/jobs/import/expression) and click on Try it out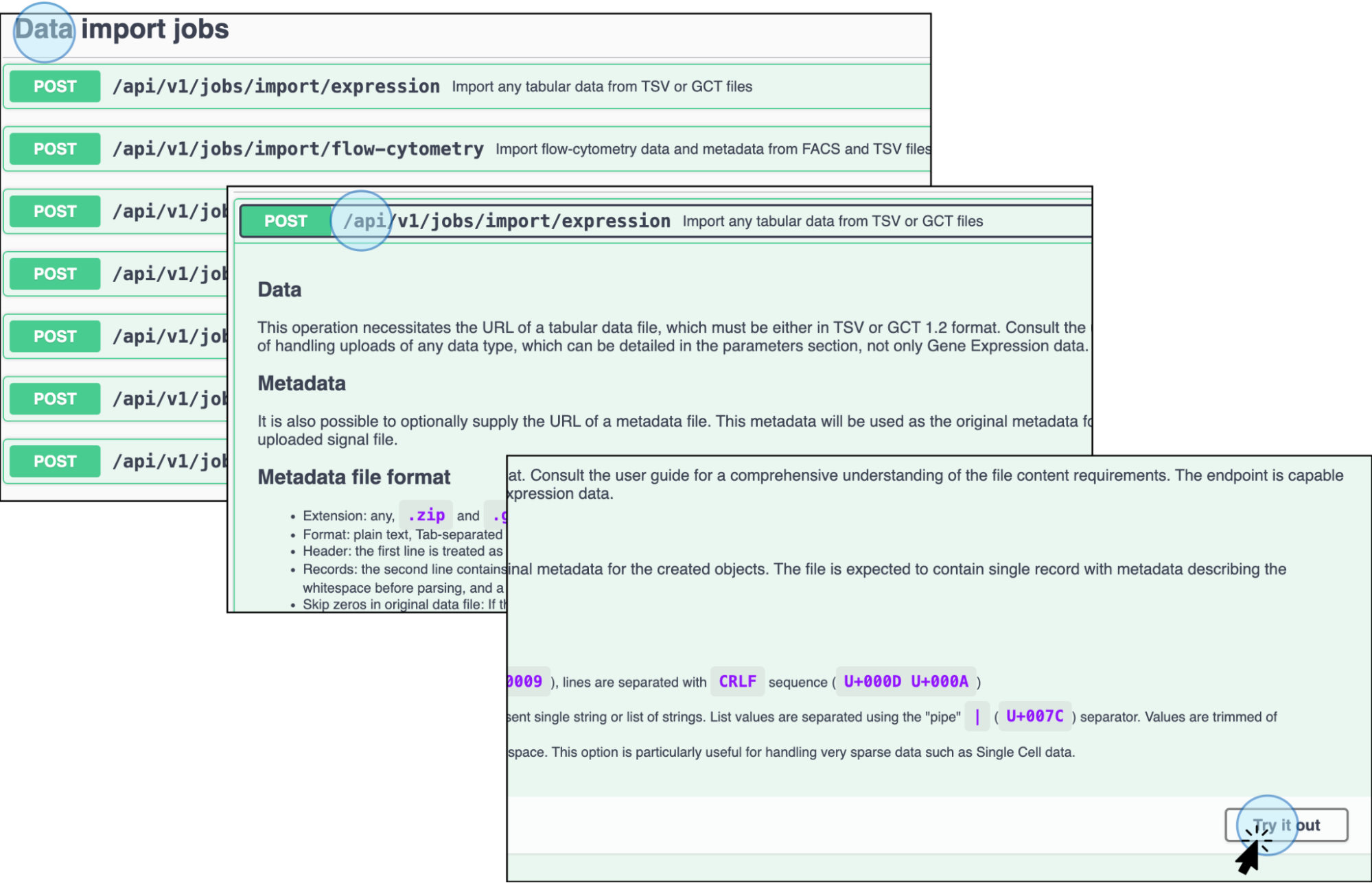
Click Import any tabular data from a TSV file or GCT files to import expression experimental data and activate it by clicking Try it out -
Enter Parameters: Indicate the required parameters: link to the data file, template, data class, etc. Optionally you can specify a link to metadata.

Enter the link for the experimental data file and details, then click Execute For all
.tsvfiles "numberOfFeatureAttributes" parameter is mandatory. -
Check the Response: The response will show that the experimental data, gene expression in this example, import has started. An execution job ID will be assigned to the import process, 1271 in this particular example. Use the ID to track the status of the import
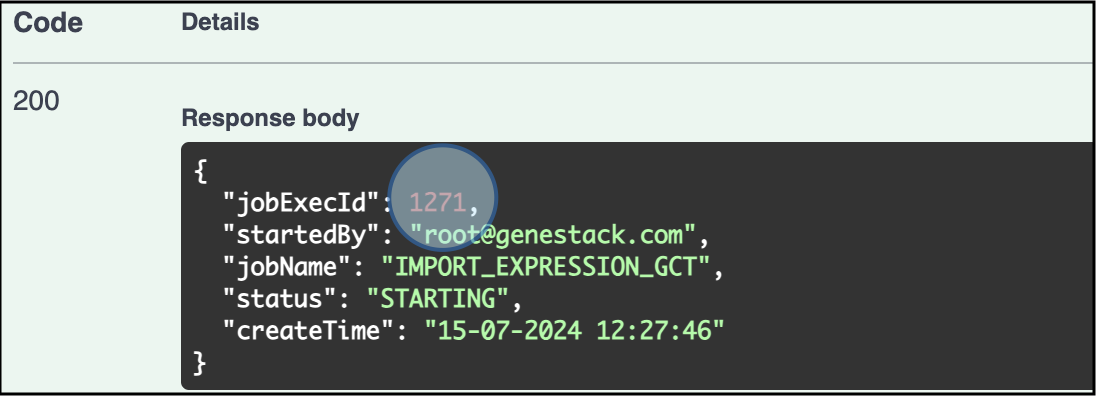
The response confirms the upload of the experimental data has started and an ID for the Job has been assigned (1271 for this example) -
Track the Import Status: You can track the status of the import with the endpoint
GET /api/v1/jobs/{jobExecId}/outputto corroborate the import process is successful and no errors were detected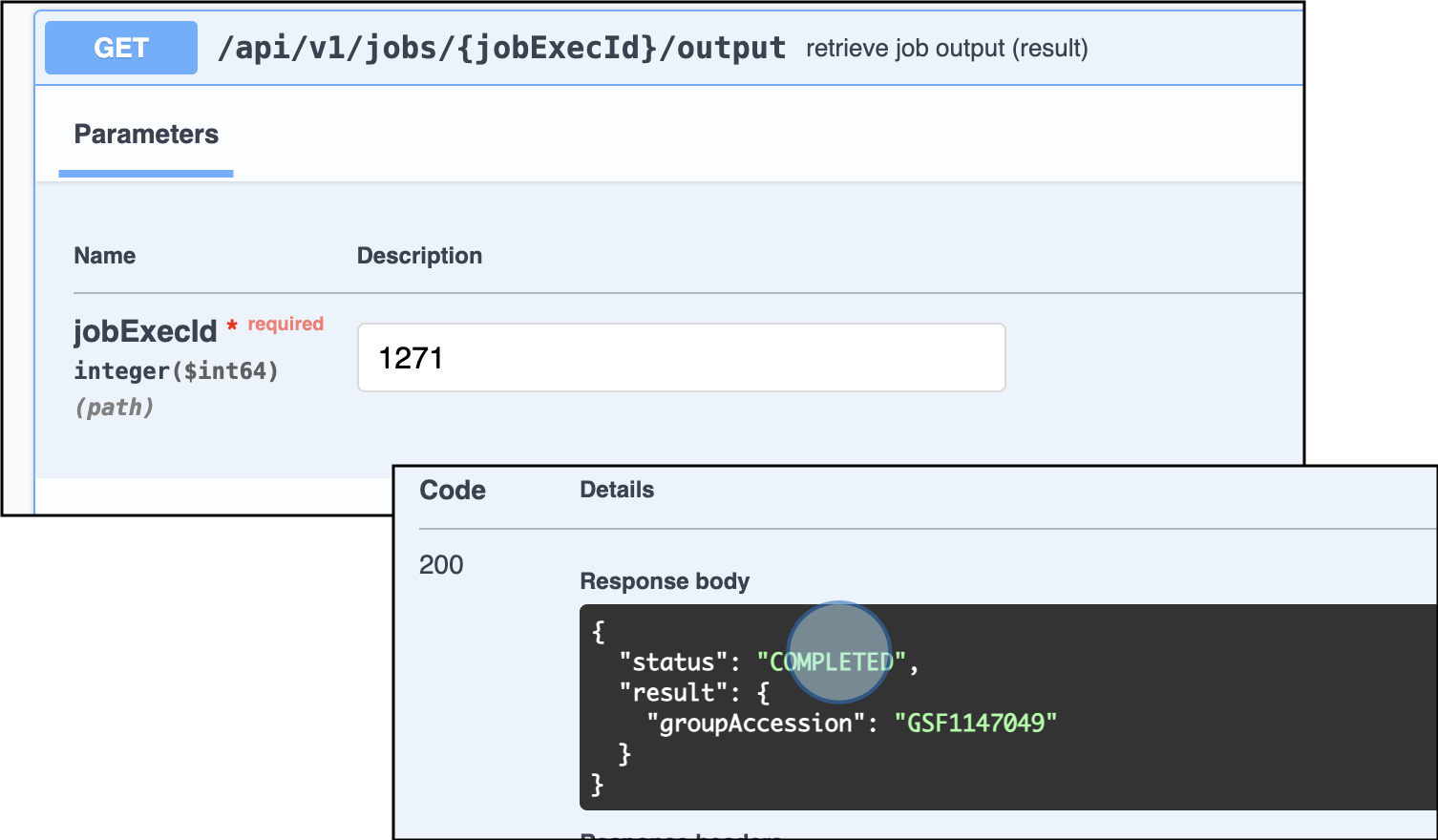
Use the endpoint GET /api/v1/jobs/{jobExecId}/output to review the status of the job import. An accession number will be assigned to the experimental data if the import is successful
Notice that an accession number was automatically assigned to the newly uploaded experimental data. This accession number will be relevant to link entities later.
Experimental Data Group Accession ID: GSF1147049
Linking your entities¶
For the ODM proper work the linkage should be done in the specified order: Samples to Studies and then Data to Samples.
-
Redirect to the Integration Curator Page: To link entities (e.g., samples and data) with the study, provide your token and authorize the execution of the selected endpoint. Identify the ID accession from the uploaded study. Note the Genestack accession values shown in the response (e.g., for sample metadata, the accession number is GSF1147034). For this particular example, these are the accession IDs:
- Study Accession ID: GSF1147033
- Sample Group Accession ID: GSF1147034
- Experimental Data Accession ID: GSF1147049
-
Integration Endpoints: Click on the integration endpoints, shown as integrationCurator. These endpoints will allow you to link data and metadata to samples and samples to studies.

The integrationCurator definition contains the integration endpoints to perform several functions as a curator, including linking entities
Link Samples and Study¶
-
Link Samples to Study: Once the samples and study are uploaded to the ODM, the next step is to link samples to study and link data to samples.
-
Identify the GroupId from the response obtained after uploading the samples (e.g., GSF1147034)
-
Select the section Sample Integration as Curator to link samples with a study. Select the endpoint Create a Link Between a Group of Sample Objects and a Study
POST /api/v1/as-curator/integration/link/sample/group/{sourceId}/to/study/{targetId}.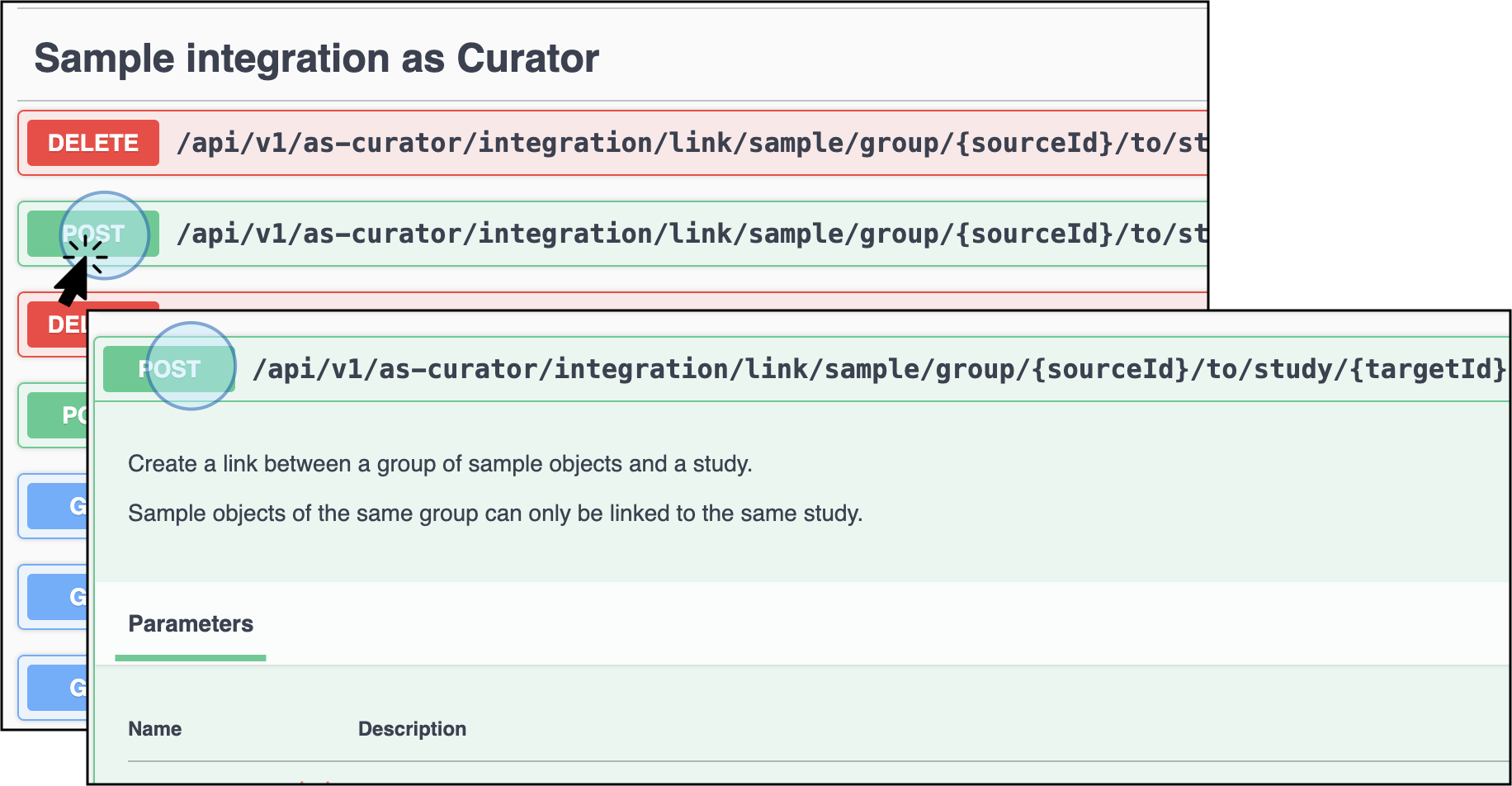
Select the Sample integration as Curator section to find the endpoint to link sample metadata with study POST /api/v1/as-curator/integration/link/sample/group/{sourceId}/to/study/{targetId} -
Enter Accession Details: Add the required values (ID accession) for the study and samples, and click Execute.
- Study Accession ID: GSF1147033
- Sample Group Accession ID: GSF1147034
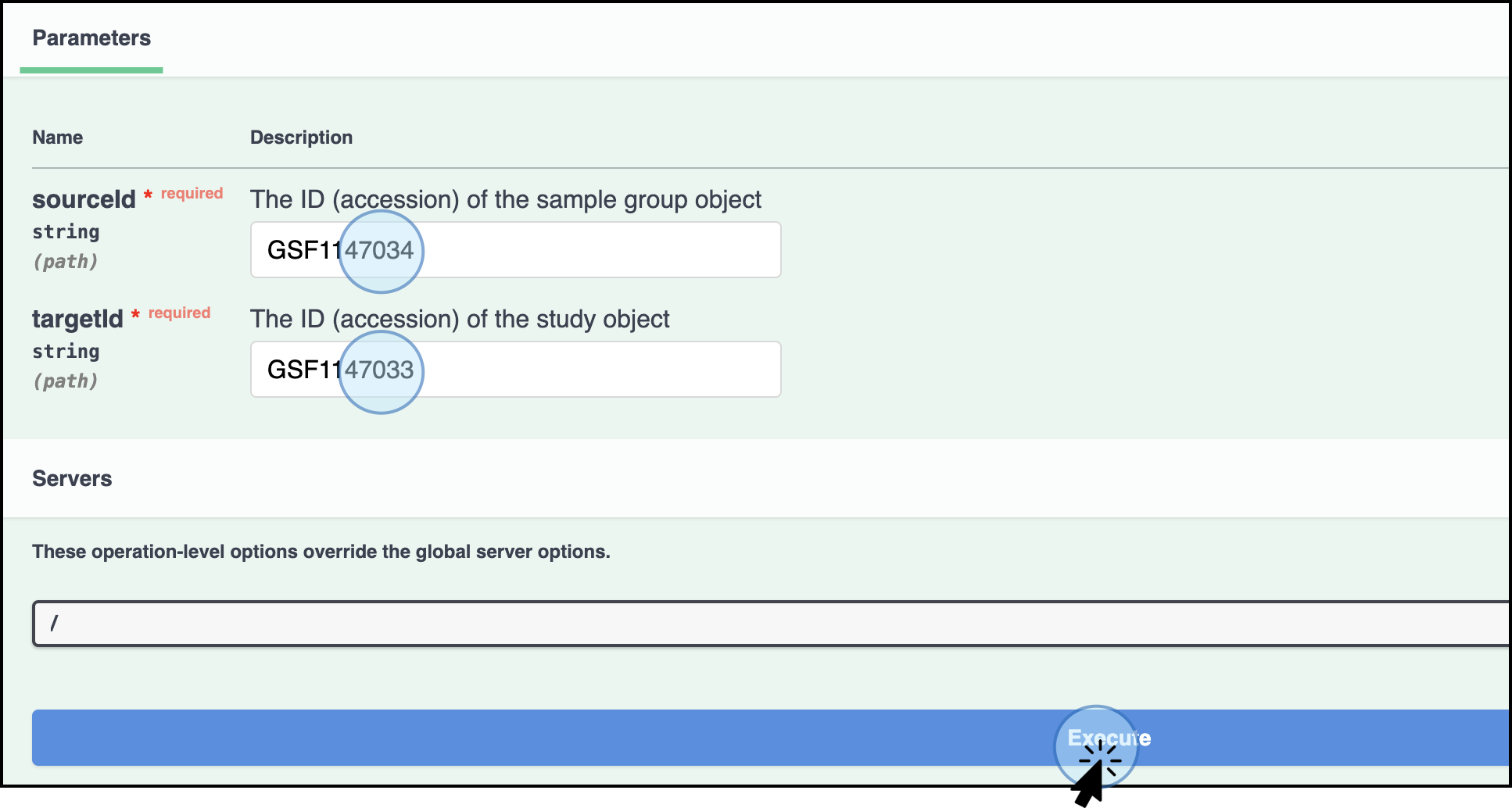
Add the details of the accession numbers from the sample group object (sourceId: GSF1147034) and the study object (targetId: GSF1147033), then click on Execute to create the link between the entities
-
Check the Response: A response will show that the link was successful.
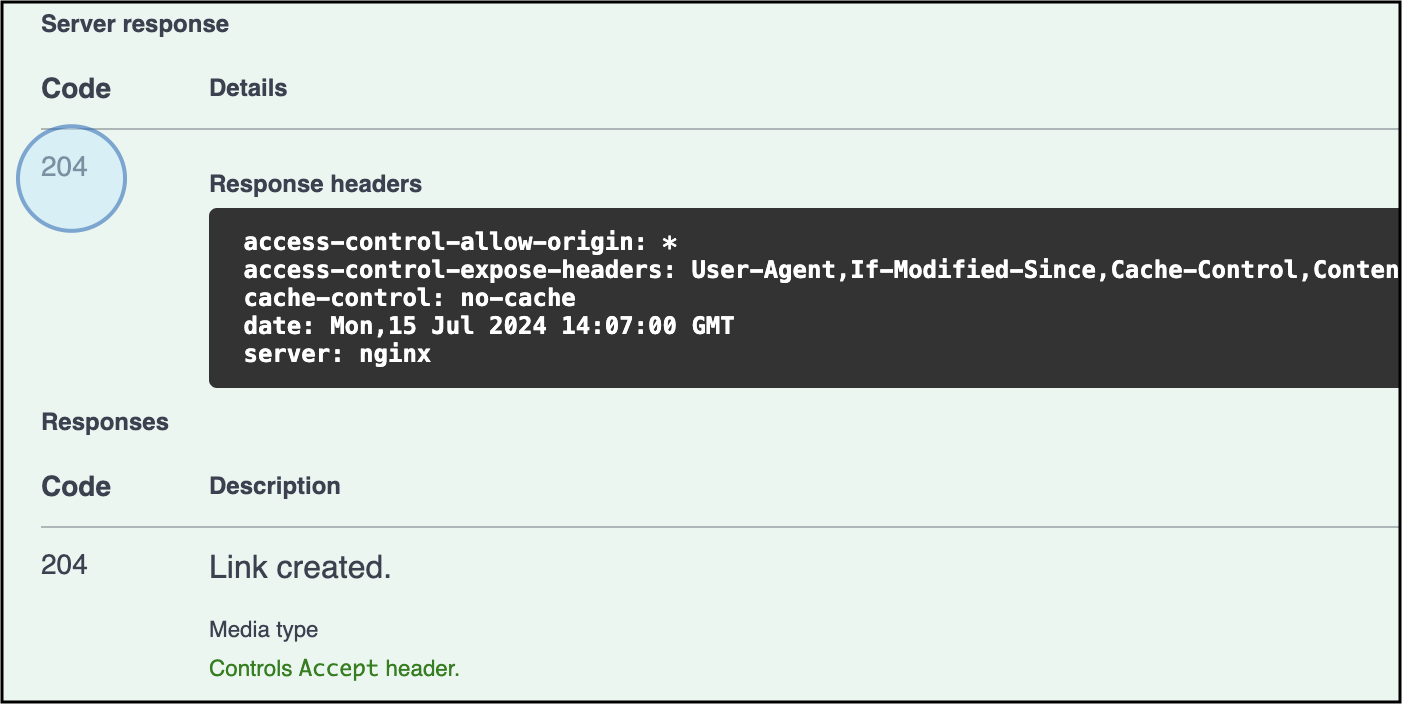
If the link is successful, a response with the code 204 will be generated -
Confirm in ODM: You can open the study in the ODM interface to see that the data is now linked.
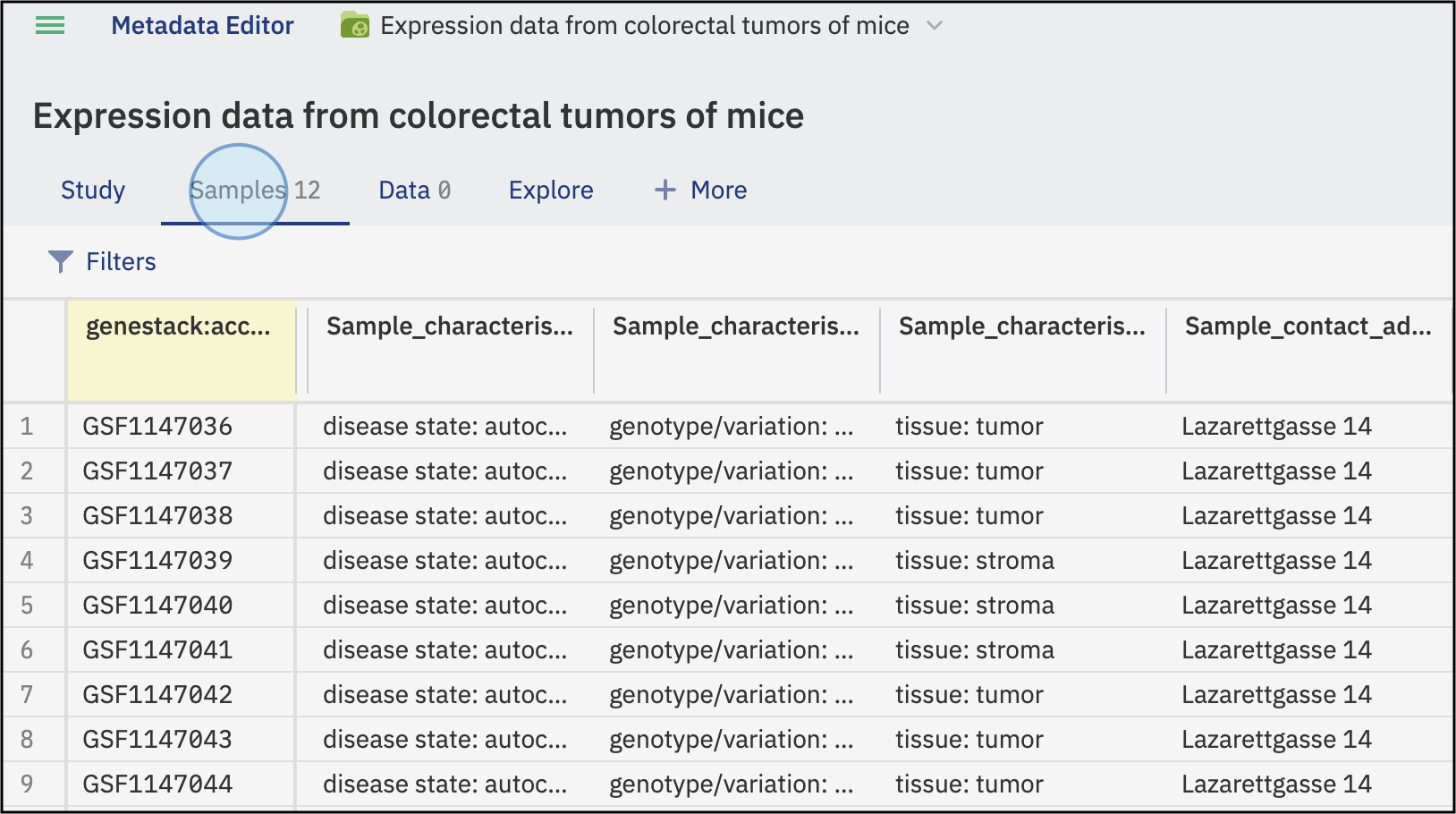
The study in ODM will now include the sample metadata that has just been linked to the study target.
Link Experimental Data and Sample Group¶
-
Identify the groupID number for the Data. For this particular example, the Data accession number is GSF1147049
- Sample Group Accession ID: GSF1147034
- Experimental Data Accession ID: GSF1147049
-
To link experimental data with samples (and the study), click on the "Expression integration as Curator" endpoints.
- Select the endpoint to create a link between data (for this specific example expression in GCT format previously uploaded) with a group of samples.
- Click on the endpoint to Create a link between a group of expression objects and a group of
samples objects:
POST /api/v1/as-curator/integration/link/expression/group/{sourceId}/to/sample/group/{targetId}
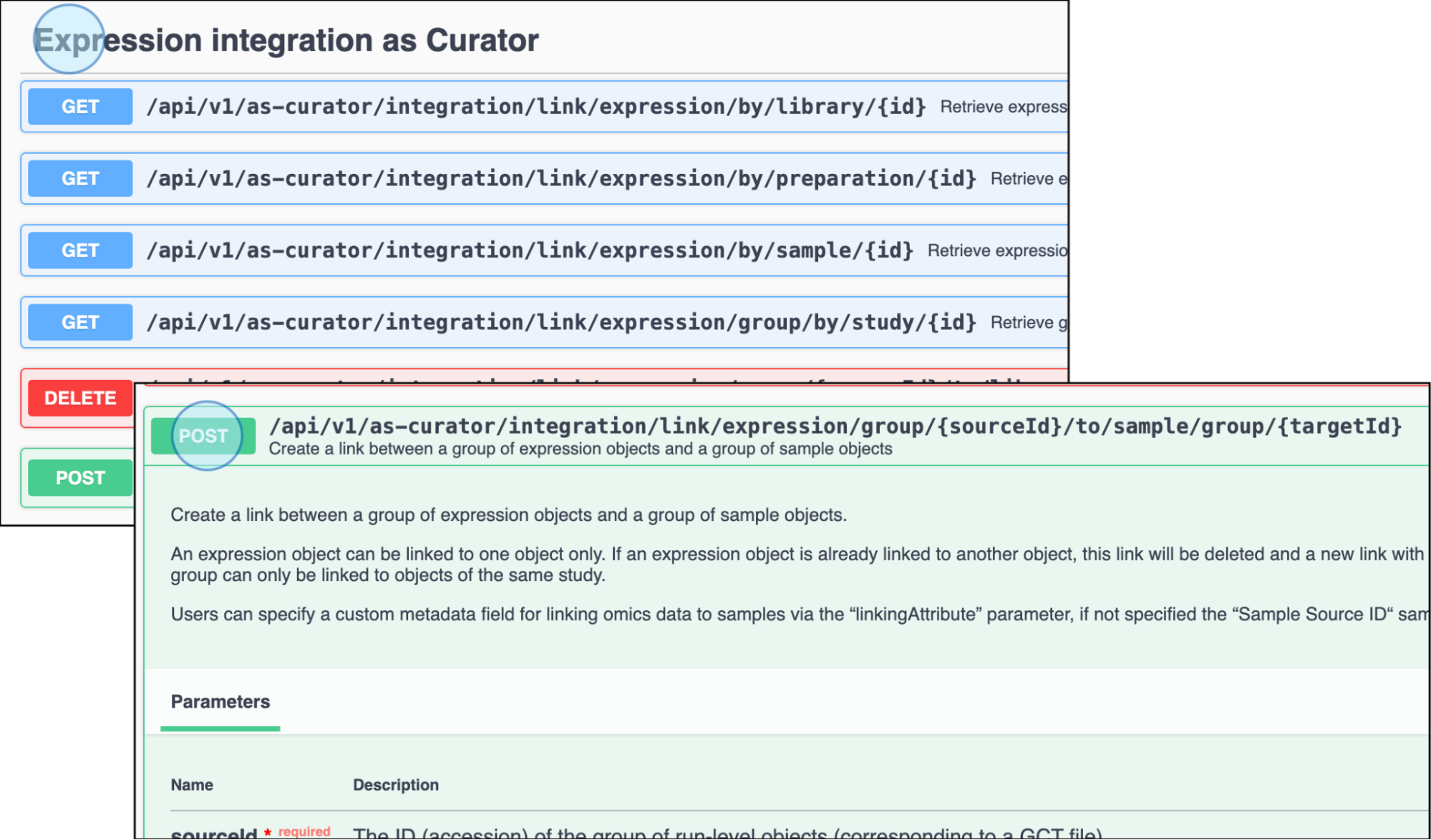
Click on Expression integration as Curator to find the endpoints to link experimental data with samples (and the study). Select the endpoint POST /api/v1/as-curator/integration/link/expression/group/{sourceId}/to/sample/group/{targetId} -
Enter Accession Details: Add the relevant information, including the data accession number and sample group accession number, and click Execute. By default, the linking attribute is the column Sample Source ID, but it can be customized.
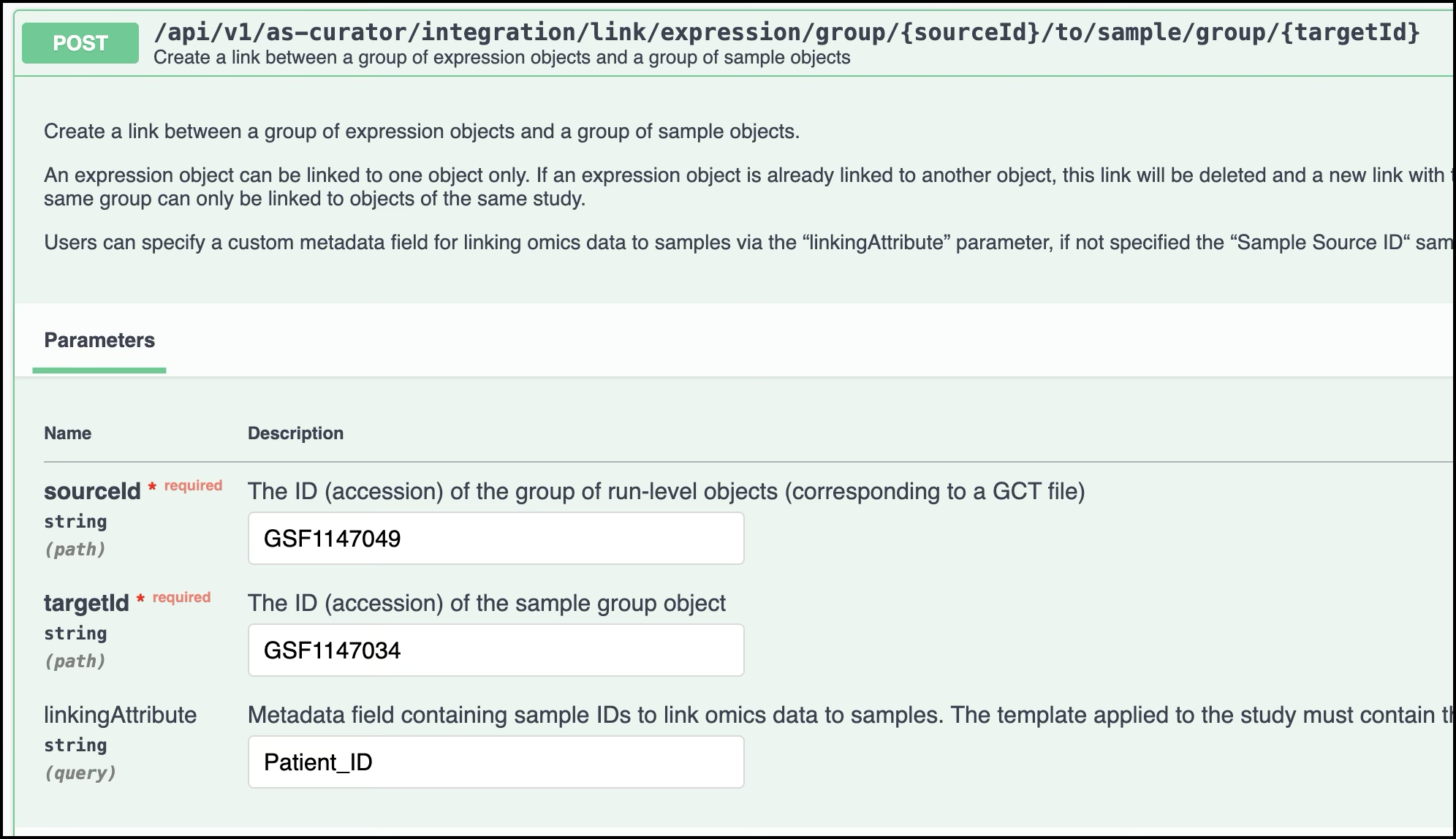
Add the details of the accession numbers corresponding to the experimental data (GSF1147049) and the sample group object (GSF1147034). By default, the linking attribute will be the column Sample Source ID, but you can customize it, for example Patient_ID -
Check the Response: The response will show that the link has been created between the group of samples and the experimental data
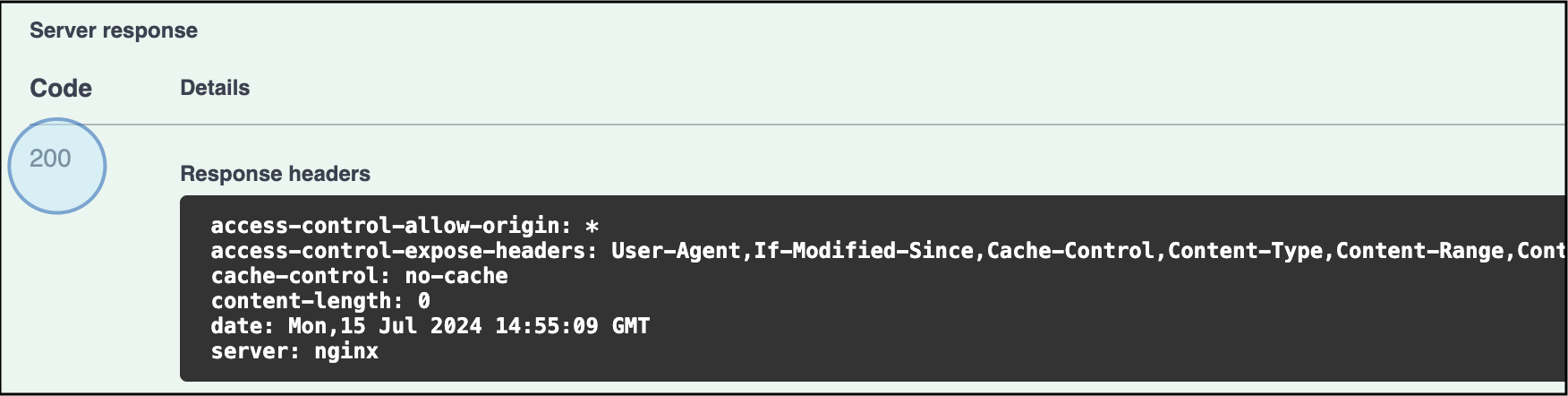
If the link is successful, a response with the code 200 will be generated -
Confirm in ODM: You can open the ODM interface to confirm that samples and experimental data are now linked to the study.
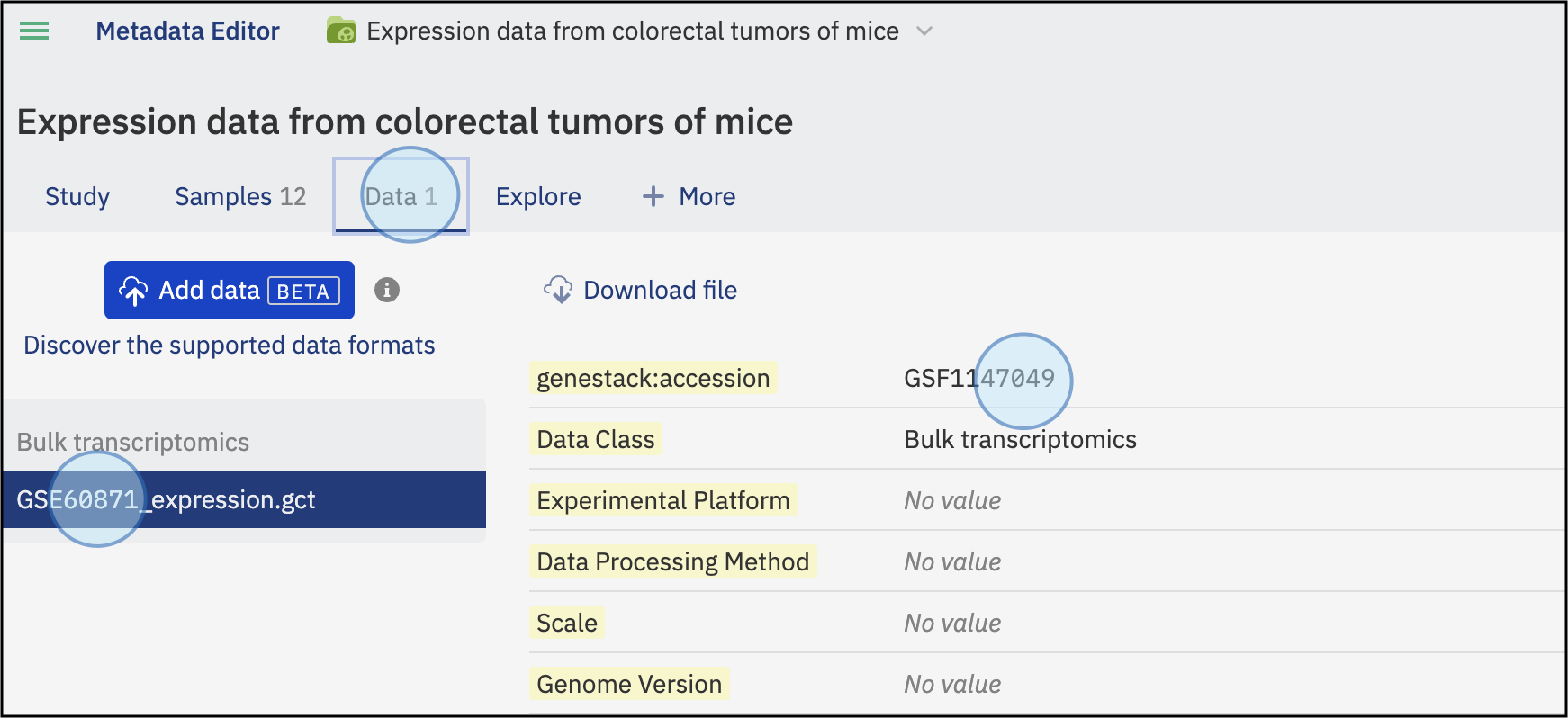
View of the study with sample metadata and experimental data (gene expression) linked
By following these steps, you can efficiently interact with the API endpoints via the Swagger interface, tailored to your role and permissions.